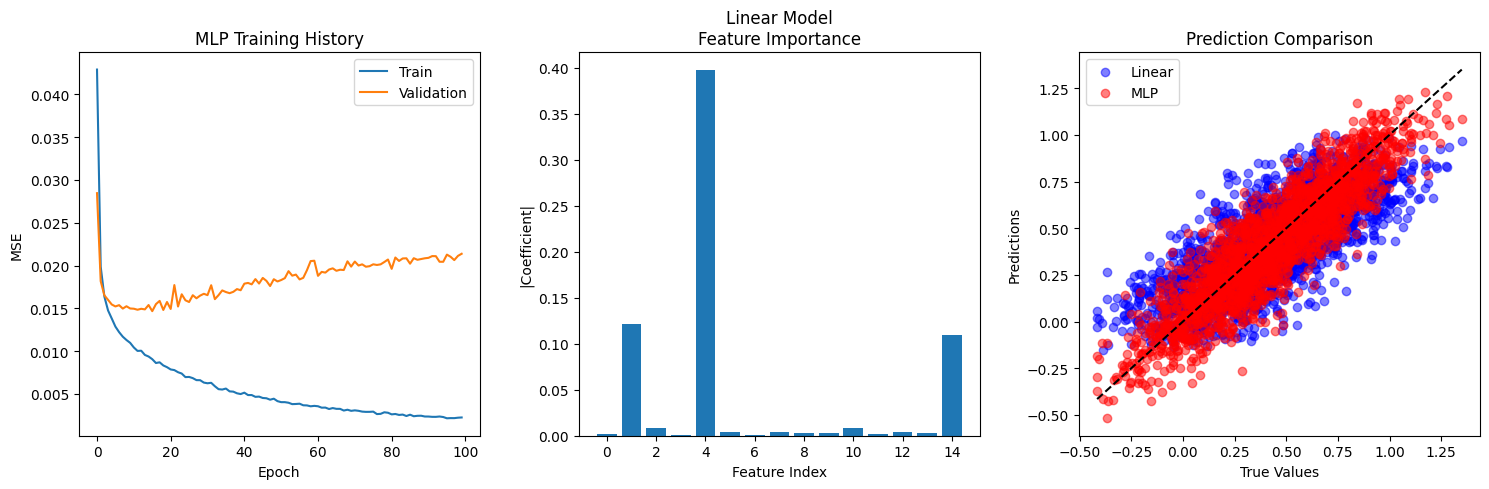
Your task is to: 1. Create a baseline linear regression model using keras.Sequential with a single Dense layer 2. Create an MLP with two hidden layers (64 and 32 units) using ReLU activation 3. Compare their performance using Mean Squared Error
250/250 ━━━━━━━━━━━━━━━━━━━━ 0s 278us/step
63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 836us/step
Model Performance Comparison:
Linear Regression:
Train MSE: 0.047476
Test MSE: 0.044473
Train R²: 0.566224
Test R²: 0.554408
MLP:
Train MSE: 0.002248
Test MSE: 0.020943
Train R²: 0.979464
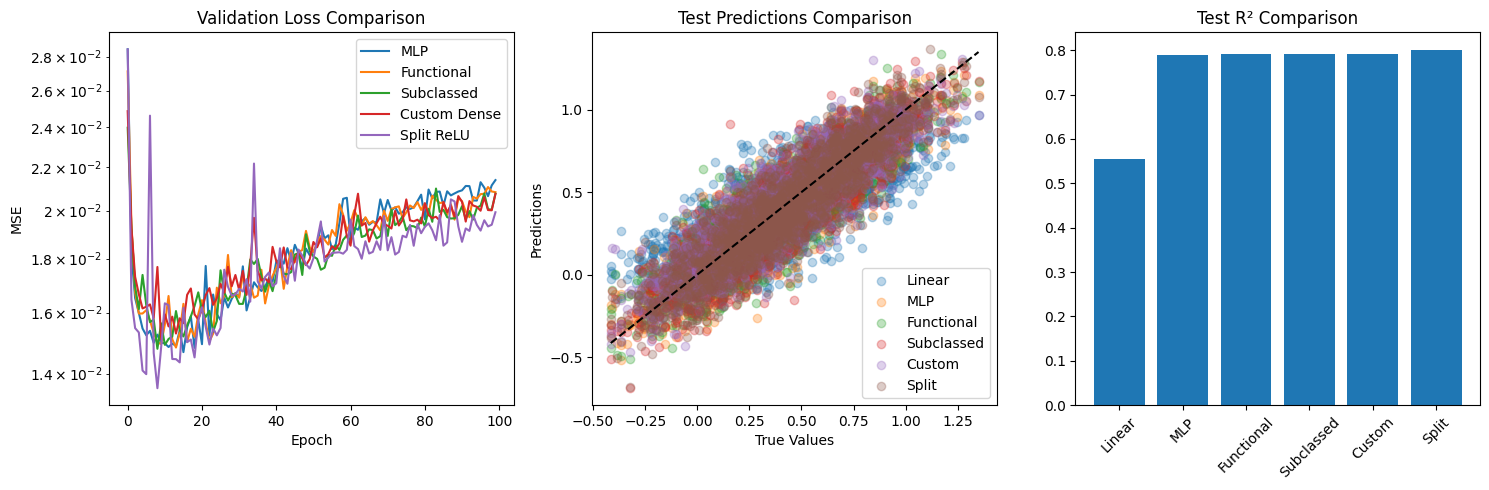
Test R²: 0.790168
Relative Improvements:
MSE Improvement: 52.9%
R² Improvement: 42.5%
Part 2: Functional API Implementation
Create a function that builds an MLP using the Functional API: - The function should accept a list of hidden layer sizes - Each hidden layer should use ReLU activation - The output layer should be linear (no activation)
250/250 ━━━━━━━━━━━━━━━━━━━━ 0s 263us/step
63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 902us/step
Functional API Model Performance:
Train MSE: 0.001665
Test MSE: 0.020820
Train R²: 0.984788
Test R²: 0.791393
Part 3: Subclassing Implementation
Create a subclass of keras.Model that implements the same MLP architecture: - Should accept list of hidden sizes in init - Define layers in init - Implement forward pass in call()
250/250 ━━━━━━━━━━━━━━━━━━━━ 0s 216us/step
63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 907us/step
Subclassed Model Performance:
Train MSE: 0.002079
Test MSE: 0.020748
Train R²: 0.981006
Test R²: 0.792121
Part 4: Custom Dense Layer
Implement your own dense layer by subclassing keras.layers.Layer: - Should accept units, activation, use_bias parameters - Implement build() method to create weights - Implement call() method for forward pass
250/250 ━━━━━━━━━━━━━━━━━━━━ 0s 240us/step
63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 826us/step
Custom Dense Model Performance:
Train MSE: 0.002145
Test MSE: 0.020742
Train R²: 0.980399
Test R²: 0.792181
Part 5: Advanced Custom Layer
Implement a custom layer that performs the following operation: Given input x, compute:
y = W₁(ReLU(x)) + W₂(ReLU(-x)) + b
where: - W₁, W₂ are learnable weight matrices - ReLU(x) = max(0, x) - b is a learnable bias vector
Mathematical formulation:
y = W₁ max(0, x) + W₂ max(0, -x) + b
This creates a “split” activation that learns different transformations for positive and negative inputs.
250/250 ━━━━━━━━━━━━━━━━━━━━ 0s 273us/step
63/63 ━━━━━━━━━━━━━━━━━━━━ 0s 869us/step
Split ReLU Model Performance:
Train MSE: 0.001488
Test MSE: 0.019924
Train R²: 0.986402
Test R²: 0.800373